GoodSAM: Bridging Domain and Capacity Gaps via Segment Anything Model for Distortion-aware Panoramic Semantic Segmentation
Accepted to CVPR 2024
-

Weiming Zhang
AI Thrust, HKUST(GZ)
-

Yexin Liu
AI Thrust, HKUST(GZ)
-

Xu Zheng
AI Thrust, HKUST(GZ)
-

Addison Lin Wang
AI & CMA Thrust, HKUST(GZ)
Dept. of CSE, HKUST

Abstract
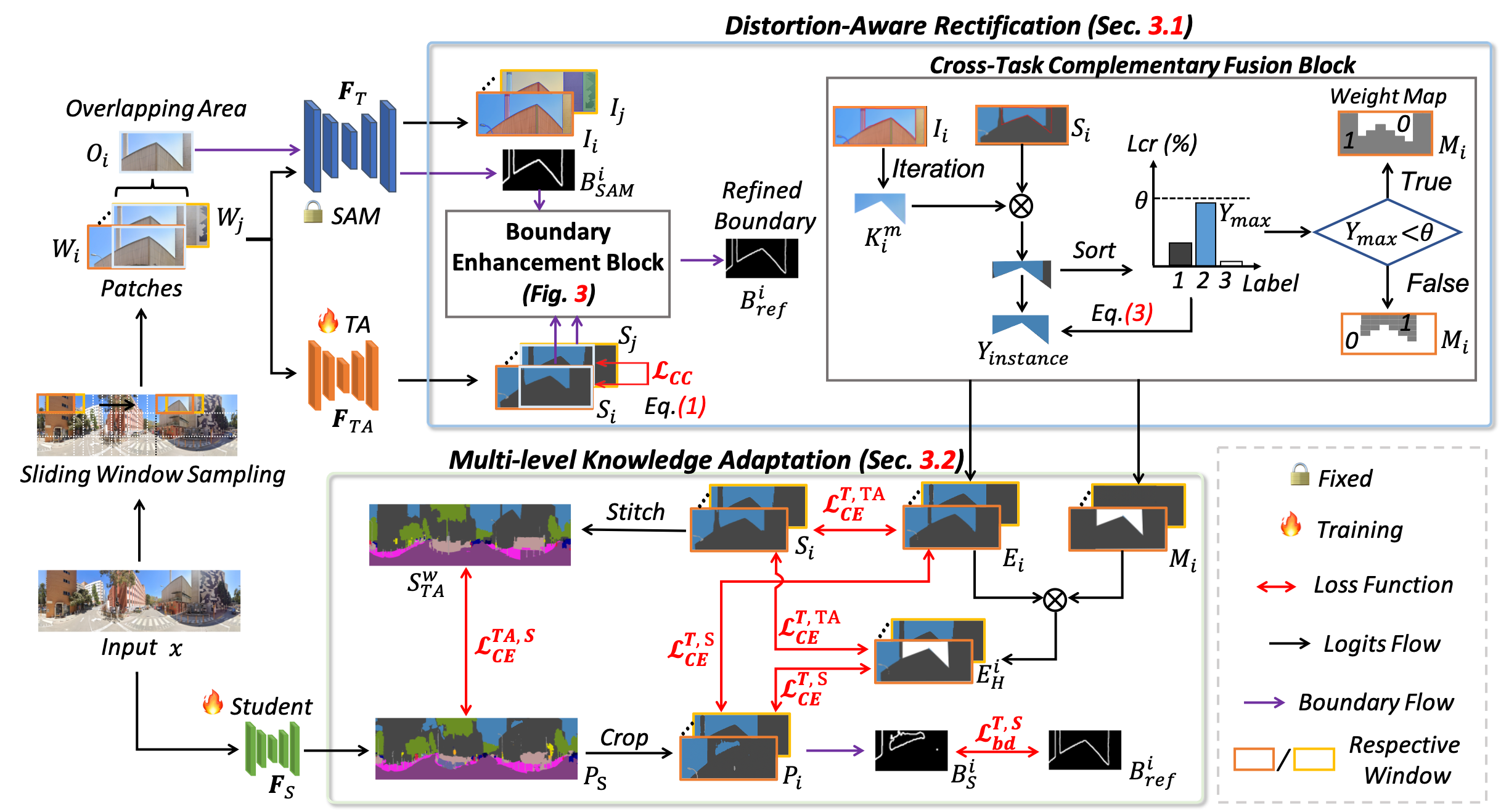
This paper tackles a novel yet challenging problem: how to transfer knowledge from the emerging Segment Anything Model (SAM) -- which reveals impressive zero-shot instance segmentation capacity -- to learn a compact panoramic semantic segmentation model, \ie, student, without requiring any labeled data. This poses considerable challenges due to SAM's inability to provide semantic labels and the large capacity gap between SAM and the student. To this end, we propose a novel framework, called GoodSAM, that introduces a teacher assistant (TA) to provide semantic information, integrated with SAM to generate ensemble logits to achieve knowledge transfer. Specifically, we propose a Distortion-Aware Rectification (DAR) module that first addresses the distortion problem of panoramic images by imposing prediction-level consistency and boundary enhancement. This subtly enhances TA's prediction capacity on panoramic images. DAR then incorporates a cross-task complementary fusion block to adaptively merge the predictions of SAM and TA to obtain more reliable ensemble logits. Moreover, we introduce a Multi-level Knowledge Adaptation (MKA) module to efficiently transfer the multi-level feature knowledge from TA and ensemble logits to learn a compact student model. Extensive experiments on two benchmarks show that our GoodSAM achieves a remarkable +3.75% mIoU improvement over the state-of-the-art (SoTA) domain adaptation methods. Also, Our most lightweight model achieves comparable performance to the SoTA methods with only 3.7M parameters.
Overall framework of our GoodSAM
An overview of our GoodSAM.